RockPaperScissorsTrainer
This example demonstrates Melodie’s Trainer module using a Rock-Paper-Scissors game model. In this model, agents start with heterogeneous payoff preferences and strategy weights. The trainer then uses a genetic algorithm (GA) to evolve these strategy parameters, aiming for higher accumulated payoffs for each agent.
Trainer: Project Structure
examples/rock_paper_scissors_trainer
├── core/
│ ├── agent.py # Defines agent's strategy, actions, and payoff logic
│ ├── data_collector.py # Collects micro and macro simulation results
│ ├── environment.py # Manages pairwise agent battles
│ ├── model.py # Contains the main simulation loop
│ ├── scenario.py # Defines scenarios and generates agent parameters
│ └── trainer.py # Configures and runs the GA-based training
├── data/
│ ├── input/
│ │ ├── SimulatorScenarios.csv
│ │ ├── TrainerScenarios.csv
│ │ └── TrainerParamsScenarios.csv
│ └── output/
└── main.py
Trainer: GA Concepts
While the Calibrator tunes parameters to match an external target, the Trainer is designed for an internal optimization process. Its goal is to allow agents to “learn” and evolve their individual behaviors to maximize their own objectives within the model’s world.
Core Idea: Maximizing Utility
Agent-Level Objective: Each agent has a goal, which is quantified by a
utilityfunction. In this example, the utility for an agent is itsaccumulated_payoffat the end of a simulation run. The Trainer’s objective is to find the behavioral parameters that maximize this utility for each agent.Parameters: You specify which agent-level parameter(s) the Trainer should evolve. Here, it’s the three strategy weights:
strategy_param_1,strategy_param_2, andstrategy_param_3.Utility Function: You must implement a
utility(agent)method. This function is called after a simulation run and must return a single float value representing that agent’s performance or “fitness.”
Genetic Algorithm (GA) for Agent Learning
The Trainer applies a separate genetic algorithm to each agent individually.
Chromosome: An agent’s set of trainable parameters (e.g., the three strategy weights) is treated as its “chromosome.”
Population: For each agent, the GA maintains a “population” of these chromosomes (i.e., different sets of strategy weights).
Fitness: To evaluate a chromosome, the model is run with the agent using that set of strategy weights. The agent’s final
utility(accumulated payoff) serves as the fitness score.Evolution: Through generations, the GA for each agent independently selects, breeds, and mutates its population of strategy weights, converging on the strategy that yields the highest personal payoff for that agent, given the behavior of all other agents.
Parameter Encoding: The Trainer uses the same binary encoding mechanism as the Calibrator to represent continuous strategy parameters for the GA. For a detailed explanation of this process, please see the Parameter Encoding: From Float to Binary section in the CovidContagionCalibrator documentation.
Parameter Configuration (`TrainerParamsScenarios.csv`)
This file controls the behavior of the genetic algorithm for all agents:
id: Unique identifier for a set of GA parameters.path_num: How many independent training processes (paths) to run. Each path is a complete run of the GA, helping to test the robustness of the evolutionary outcome.generation_num: The number of generations the GA will run for.strategy_population: The size of the chromosome population maintained for each agent.mutation_prob: The probability of random mutations.strategy_param_code_length: The precision of the strategy parameters.strategy_param_1_min/max, etc.: These define the search space bounds for each parameter being trained.
Trainer: How It Works
Simulation Loop: In each period, agents normalize their strategy weights into action probabilities (rock, paper, or scissors). They are then randomly paired to play one round, and their payoffs are recorded. At the end of the simulation run, each agent’s long-term share of actions is calculated.
Training Loop: The
RPSTrainerevolves the strategy parameters for every agent. The fitness is each agent’saccumulated_payoff. Training settings come fromTrainerParamsScenarios.csv.Input Data: The scenarios for the simulator and trainer are defined in their respective CSV files. Agent-level parameters are generated dynamically within the
RPSScenarioclass.agent_nummust be an even number, as agents are paired up in each period.
Trainer: Results
The following plots, taken from the original model, show the evolution of the mean and coefficient of variance for the total accumulated payoff across all agents. This illustrates the effectiveness of the training process.
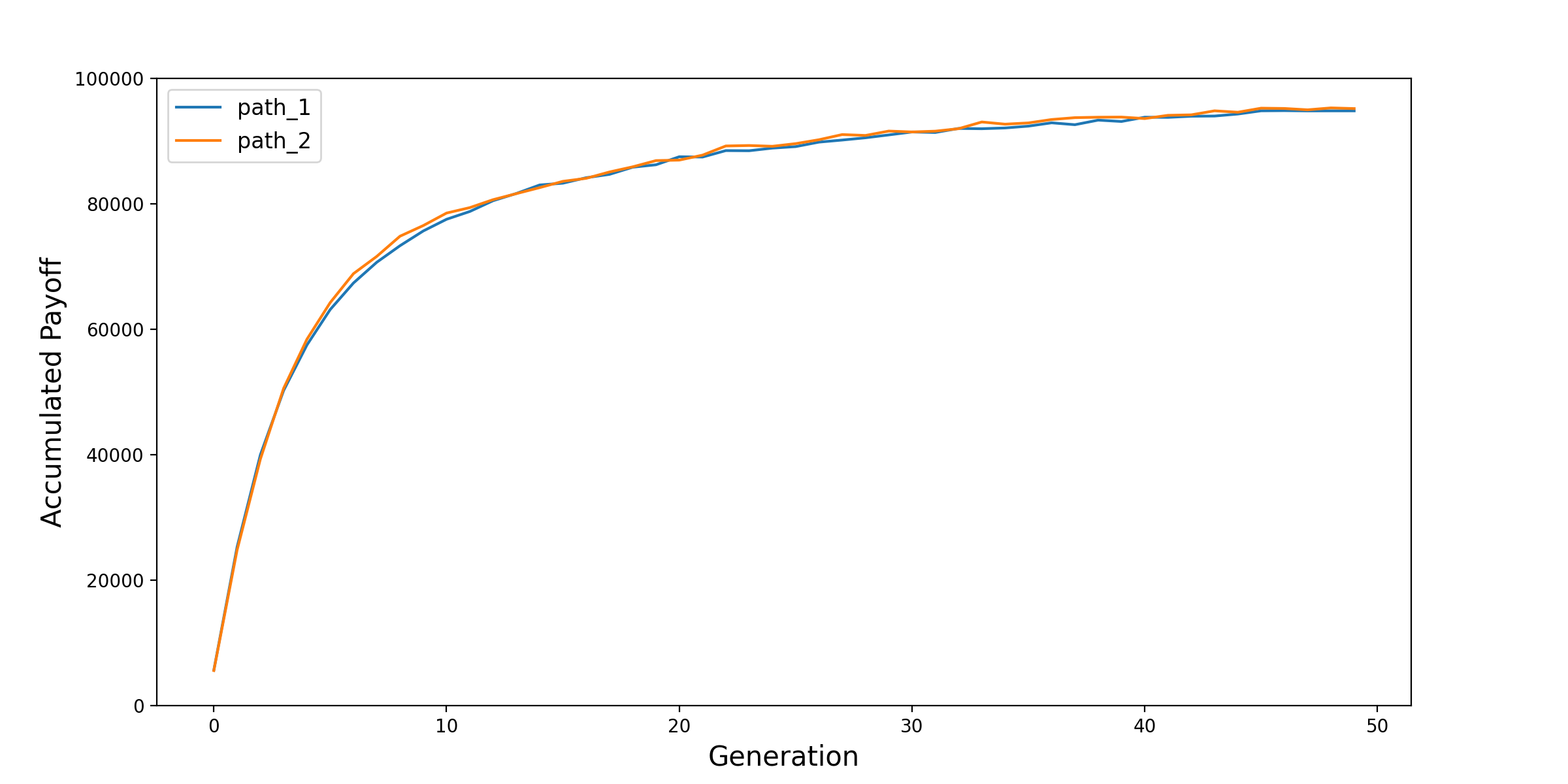
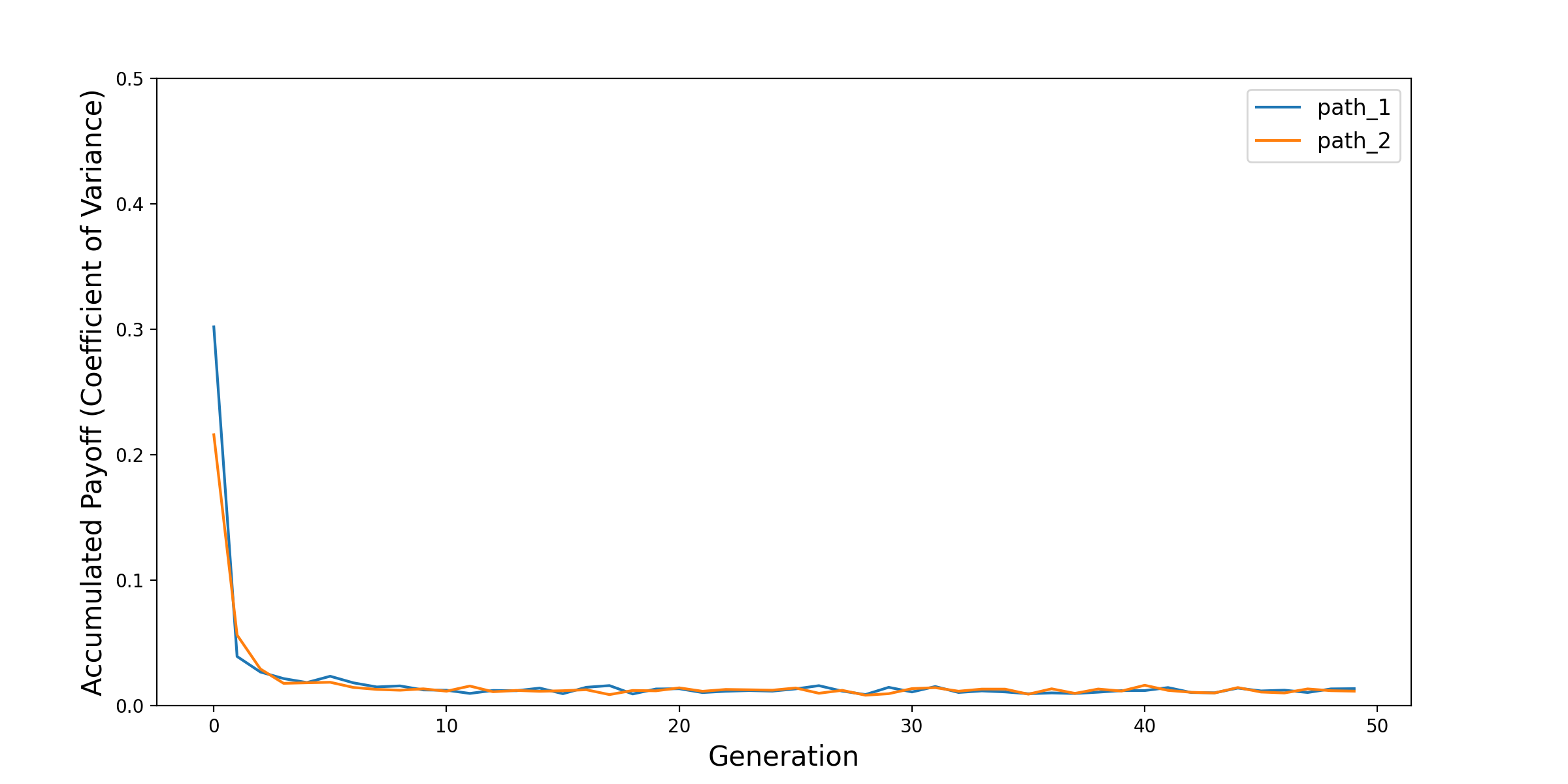
Trainer: Running the Model
You can run both the simulator and the trainer using the main script:
python -m examples.rock_paper_scissors_trainer.main
The trainer clears the output directory before it runs. Therefore, after executing the command, you will only find the trainer’s output tables in examples/rock_paper_scissors_trainer/data/output. If you need the simulator’s results, you should run it separately (for example, by commenting out the run_trainer call in main.py).
Parallel Execution Mode
The Trainer supports two parallelization modes, controlled by the optional parallel_mode parameter when creating the trainer instance:
``parallel_mode=”process”``: Uses subprocess-based parallelism via
multiprocessing. This is the traditional approach and works on all Python versions.``parallel_mode=”thread”``: Uses thread-based parallelism via
ThreadPoolExecutor. This is the default mode on Python 3.13+.``parallel_mode=None`` (default): Lets Melodie choose automatically. It selects
"thread"on Python 3.13+ and"process"on older Python versions.
You can specify the mode when creating the trainer:
trainer = RPSTrainer(
config=cfg,
scenario_cls=RPSScenario,
model_cls=RPSModel,
processors=4,
parallel_mode="thread", # or "process"; omit to auto-select
)
Trainer: Code
This section shows the key code implementation for the trainer model.
Model Structure
Defined in core/model.py.
1from typing import TYPE_CHECKING
2
3from Melodie import Model
4
5from examples.rock_paper_scissors_trainer.core.agent import RPSAgent
6from examples.rock_paper_scissors_trainer.core.data_collector import RPSDataCollector
7from examples.rock_paper_scissors_trainer.core.environment import RPSEnvironment
8from examples.rock_paper_scissors_trainer.core.scenario import RPSScenario
9
10if TYPE_CHECKING:
11 from Melodie import AgentList
12
13
14class RPSModel(Model):
15 """
16 The main model class for the Rock-Paper-Scissors simulation.
17
18 It sets up the agents, environment, and data collector, and defines the
19 main simulation loop that runs for a specified number of periods.
20 """
21
22 scenario: "RPSScenario"
23 data_collector: RPSDataCollector
24
25 def create(self) -> None:
26 self.agents: "AgentList[RPSAgent]" = self.create_agent_list(RPSAgent)
27 self.environment: RPSEnvironment = self.create_environment(RPSEnvironment)
28 self.data_collector = self.create_data_collector(RPSDataCollector)
29
30 def setup(self) -> None:
31 # Populates the agent list using the dynamically generated parameter table
32 # from the scenario.
33 self.agents.setup_agents(
34 agents_num=self.scenario.agent_num,
35 params_df=self.scenario.agent_params,
36 )
37
38 def run(self) -> None:
39 """Executes the main simulation loop for `scenario.period_num` periods."""
40 for period in range(self.scenario.period_num):
41 self.environment.agents_setup_data(self.agents)
42 self.environment.run_game_rounds(self.agents)
43 self.environment.agents_calc_action_share(period, self.agents)
44 self.data_collector.collect(period)
45 self.data_collector.save()
46
Environment Logic
Defined in core/environment.py.
1import random
2from typing import TYPE_CHECKING
3
4from Melodie import AgentList, Environment
5
6from examples.rock_paper_scissors_trainer.core.agent import RPSAgent
7
8if TYPE_CHECKING:
9 from examples.rock_paper_scissors_trainer.core.scenario import RPSScenario
10
11
12class RPSEnvironment(Environment):
13 """
14 The environment for the Rock-Paper-Scissors model.
15
16 It is responsible for orchestrating the agent interactions by randomly
17 pairing them up for battles in each period. It also tracks the total
18 accumulated payoff across all agents as a macro-level indicator.
19 """
20
21 scenario: "RPSScenario"
22
23 def setup(self) -> None:
24 """Initializes environment-level properties."""
25 self.total_accumulated_payoff = 0.0
26
27 @staticmethod
28 def agents_setup_data(agents: "AgentList[RPSAgent]") -> None:
29 """
30 Prepares derived variables for all agents at the beginning of each period.
31 """
32 for agent in agents:
33 agent.setup_action_prob()
34 agent.setup_action_payoff()
35
36 def run_game_rounds(self, agents: "AgentList[RPSAgent]") -> None:
37 """
38 In each period, randomly pairs up all agents to play one round of the game.
39 """
40 assert self.scenario.agent_num % 2 == 0, "scenario.agent_num must be even."
41 agent_ids = list(range(self.scenario.agent_num))
42 random.shuffle(agent_ids)
43 for idx in range(0, len(agent_ids), 2):
44 opponent_idx = idx + 1
45 if opponent_idx >= len(agent_ids):
46 break
47 self.agents_battle(agents[agent_ids[idx]], agents[agent_ids[opponent_idx]])
48
49 def agents_battle(self, agent_1: "RPSAgent", agent_2: "RPSAgent") -> None:
50 """
51 Executes a single battle between two agents, determines the outcome,
52 and updates their payoffs.
53 """
54 agent_1.id_competitor = agent_2.id
55 agent_2.id_competitor = agent_1.id
56
57 agent_1.select_action()
58 agent_2.select_action()
59
60 if agent_1.action == agent_2.action:
61 agent_1.result = agent_2.result = "tie"
62 elif (
63 (agent_1.action == "rock" and agent_2.action == "paper")
64 or (agent_1.action == "paper" and agent_2.action == "scissors")
65 or (agent_1.action == "scissors" and agent_2.action == "rock")
66 ):
67 agent_1.result = "lose"
68 agent_2.result = "win"
69 else:
70 agent_1.result = "win"
71 agent_2.result = "lose"
72
73 agent_1.set_action_payoff()
74 agent_2.set_action_payoff()
75 self.total_accumulated_payoff += agent_1.payoff + agent_2.payoff
76
77 def agents_calc_action_share(self, period: int, agents: "AgentList[RPSAgent]") -> None:
78 """
79 Triggers the calculation of action shares for all agents at the very
80 end of the simulation run.
81 """
82 if period == self.scenario.period_num - 1:
83 for agent in agents:
84 agent.calc_action_percentage()
85
Agent Behavior
Defined in core/agent.py.
1import random
2from typing import Dict, Tuple, TYPE_CHECKING
3
4from Melodie import Agent
5
6if TYPE_CHECKING:
7 from examples.rock_paper_scissors_trainer.core.scenario import RPSScenario
8
9
10class RPSAgent(Agent):
11 """
12 Represents an agent playing the Rock-Paper-Scissors game.
13
14 Each agent has its own unique payoff settings for winning, losing, or tying,
15 as well as three strategy parameters that determine the probabilities of
16 choosing rock, paper, or scissors. These strategy parameters are the target
17 for the evolutionary training by the Trainer module. The agent also tracks
18 its own play history and accumulated payoffs.
19 """
20
21 scenario: "RPSScenario"
22
23 def setup(self) -> None:
24 # Payoff settings injected via agent params dataframe.
25 self.payoff_rock_win: float = 0.0
26 self.payoff_rock_lose: float = 0.0
27 self.payoff_paper_win: float = 0.0
28 self.payoff_paper_lose: float = 0.0
29 self.payoff_scissors_win: float = 0.0
30 self.payoff_scissors_lose: float = 0.0
31 self.payoff_tie: float = 0.0
32
33 # Strategy weights to be trained by the Trainer.
34 self.strategy_param_1: float = 0.0
35 self.strategy_param_2: float = 0.0
36 self.strategy_param_3: float = 0.0
37
38 self._reset_counters()
39
40 def _reset_counters(self) -> None:
41 """Initializes or resets the agent's state for a new simulation run."""
42 self.id_competitor: int = 0
43 self.action: str = ""
44 self.result: str = ""
45 self.payoff: float = 0.0
46 self.accumulated_payoff: float = 0.0
47 self.n_rock: int = 0
48 self.n_paper: int = 0
49 self.n_scissors: int = 0
50 self.share_rock: float = 0.0
51 self.share_paper: float = 0.0
52 self.share_scissors: float = 0.0
53
54 def setup_action_prob(self) -> None:
55 """
56 Normalizes the three strategy parameters into a probability distribution
57 for choosing rock, paper, or scissors.
58 """
59 if self.strategy_param_1 == self.strategy_param_2 == self.strategy_param_3 == 0:
60 # Avoid division by zero if a chromosome is all zeros during training.
61 self.strategy_param_1 = self.strategy_param_2 = self.strategy_param_3 = 1.0
62 total = self.strategy_param_1 + self.strategy_param_2 + self.strategy_param_3
63 self.action_prob = {
64 "rock": self.strategy_param_1 / total,
65 "paper": self.strategy_param_2 / total,
66 "scissors": self.strategy_param_3 / total,
67 }
68
69 def setup_action_payoff(self) -> None:
70 """
71 Creates a lookup dictionary that maps (action, outcome) pairs to their
72 corresponding payoffs. This helps to keep the battle logic clean.
73 """
74 self.action_payoff: Dict[Tuple[str, str], float] = {
75 ("rock", "win"): self.payoff_rock_win,
76 ("rock", "lose"): self.payoff_rock_lose,
77 ("paper", "win"): self.payoff_paper_win,
78 ("paper", "lose"): self.payoff_paper_lose,
79 ("scissors", "win"): self.payoff_scissors_win,
80 ("scissors", "lose"): self.payoff_scissors_lose,
81 ("rock", "tie"): self.payoff_tie,
82 ("paper", "tie"): self.payoff_tie,
83 ("scissors", "tie"): self.payoff_tie,
84 }
85
86 def select_action(self) -> None:
87 """
88 Selects an action (rock, paper, or scissors) based on the current
89 strategy probabilities and updates the action counter.
90 """
91 rand = random.random()
92 if rand <= self.action_prob["rock"]:
93 self.action = "rock"
94 self.n_rock += 1
95 elif rand <= self.action_prob["rock"] + self.action_prob["paper"]:
96 self.action = "paper"
97 self.n_paper += 1
98 else:
99 self.action = "scissors"
100 self.n_scissors += 1
101
102 def set_action_payoff(self) -> None:
103 """
104 Records the payoff for the last action taken and adds it to the
105 accumulated payoff for the current simulation run.
106 """
107 self.payoff = self.action_payoff[(self.action, self.result)]
108 self.accumulated_payoff += self.payoff
109
110 def calc_action_percentage(self) -> None:
111 """
112 Calculates the agent's long-term share of each action at the end of a
113 simulation run. This is useful for analyzing the evolved strategies.
114 """
115 if self.scenario.period_num > 0:
116 self.share_rock = self.n_rock / self.scenario.period_num
117 self.share_paper = self.n_paper / self.scenario.period_num
118 self.share_scissors = self.n_scissors / self.scenario.period_num
119
Data Collection Setup
Defined in core/data_collector.py.
1from Melodie import DataCollector
2
3
4class RPSDataCollector(DataCollector):
5 """
6 A custom data collector for the Rock-Paper-Scissors model.
7
8 It is configured to save detailed agent-level data about each game round
9 (e.g., opponent, action, result, payoff) as well as the final evolved
10 strategy shares. It also records the environment-level total payoff.
11 """
12
13 def setup(self) -> None:
14 self.add_agent_property("agents", "id_competitor")
15 self.add_agent_property("agents", "action")
16 self.add_agent_property("agents", "n_rock")
17 self.add_agent_property("agents", "n_paper")
18 self.add_agent_property("agents", "n_scissors")
19 self.add_agent_property("agents", "result")
20 self.add_agent_property("agents", "payoff")
21 self.add_agent_property("agents", "accumulated_payoff")
22 self.add_agent_property("agents", "share_rock")
23 self.add_agent_property("agents", "share_paper")
24 self.add_agent_property("agents", "share_scissors")
25 self.add_environment_property("total_accumulated_payoff")
26
Scenario Definition
Defined in core/scenario.py.
1from typing import Any, Dict
2
3import numpy as np
4import pandas as pd
5from Melodie import Scenario
6
7
8class RPSScenario(Scenario):
9 """
10 Defines and manages scenarios for the Rock-Paper-Scissors model.
11
12 This class handles loading all input data and, notably, dynamically
13 generates the agent parameter dataframe for each scenario. This approach
14 is used instead of a static input file to ensure that each simulation
15 run uses a unique but reproducible set of heterogeneous agent parameters
16 based on the scenario's defined bounds.
17 """
18
19 def setup(self):
20 # Payoff parameters, loaded from scenario tables.
21 self.payoff_win_min = 0.0
22 self.payoff_win_max = 0.0
23 self.payoff_lose_min = 0.0
24 self.payoff_lose_max = 0.0
25 self.payoff_tie = 0.0
26
27 def load_data(self) -> None:
28 self.agent_params = self._generate_agent_params()
29
30 def _generate_agent_params(self) -> pd.DataFrame:
31 """
32 Dynamically builds the agent parameter dataframe.
33
34 For each agent, it generates random payoff values within the bounds
35 specified by the current scenario (`self.payoff_win_min`, etc.) and
36 initial random strategy parameters. Using the scenario `id` as a seed
37 for the random number generator ensures that the parameter set is
38 reproducible for each specific scenario.
39 """
40 assert self.agent_num > 0, "agent_num must be positive."
41 rng = np.random.default_rng(self.id)
42
43 def generator(agent_id: int) -> Dict[str, Any]:
44 return {
45 "id": agent_id,
46 "id_scenario": self.id,
47 "payoff_rock_win": rng.uniform(self.payoff_win_min, self.payoff_win_max),
48 "payoff_rock_lose": rng.uniform(self.payoff_lose_min, self.payoff_lose_max),
49 "payoff_paper_win": rng.uniform(self.payoff_win_min, self.payoff_win_max),
50 "payoff_paper_lose": rng.uniform(self.payoff_lose_min, self.payoff_lose_max),
51 "payoff_scissors_win": rng.uniform(self.payoff_win_min, self.payoff_win_max),
52 "payoff_scissors_lose": rng.uniform(self.payoff_lose_min, self.payoff_lose_max),
53 "payoff_tie": self.payoff_tie,
54 "strategy_param_1": rng.uniform(0, 100),
55 "strategy_param_2": rng.uniform(0, 100),
56 "strategy_param_3": rng.uniform(0, 100),
57 }
58
59 return pd.DataFrame(generator(agent_id) for agent_id in range(self.agent_num))
60
Trainer Definition
Defined in core/trainer.py.
1from Melodie import Trainer
2
3from examples.rock_paper_scissors_trainer.core.agent import RPSAgent
4
5
6class RPSTrainer(Trainer):
7 """
8 A custom Trainer for evolving agents' strategies in the Rock-Paper-Scissors model.
9
10 This trainer uses a genetic algorithm to tune the three strategy parameters
11 for each agent. The goal is to maximize the agent's final accumulated payoff,
12 which serves as the fitness function for the evolutionary process.
13 """
14
15 def setup(self) -> None:
16 # Configures the trainer to target the three strategy parameters for all
17 # agents in the 'agents' list.
18 self.add_agent_training_property(
19 "agents",
20 ["strategy_param_1", "strategy_param_2", "strategy_param_3"],
21 lambda scenario: list(range(scenario.agent_num)),
22 )
23
24 def collect_data(self) -> None:
25 # Specifies which properties to save during the training process.
26 # This allows for analysis of how strategies and outcomes evolve over generations.
27 self.add_agent_property("agents", "strategy_param_1")
28 self.add_agent_property("agents", "strategy_param_2")
29 self.add_agent_property("agents", "strategy_param_3")
30 self.add_agent_property("agents", "share_rock")
31 self.add_agent_property("agents", "share_paper")
32 self.add_agent_property("agents", "share_scissors")
33 self.add_environment_property("total_accumulated_payoff")
34
35 def utility(self, agent: RPSAgent) -> float:
36 """
37 Defines the fitness function for the genetic algorithm.
38
39 The trainer will aim to maximize this value. In this model, the fitness
40 is simply the agent's total accumulated payoff at the end of a simulation run.
41 """
42 return agent.accumulated_payoff
43